

When it comes to payment and billing applications, not only is availability crucial, but development teams need to build idempotency into their system to guarantee data correctness.
At a high level, idempotency is a property of an operation that allows it to be applied multiple times without changing the result. When it’s built into the system, you can avoid errors (duplicate payments, incorrect balances, etc.) that will frustrate customers. However, achieving idempotency can be difficult if you have a distributed system that’s processing a high volume of competing transactions.
In a distributed system, multiple nodes may be executing the same operation at the same time (concurrently). If the operation is idempotent, the nodes can execute in parallel without any risk of inconsistency. But if the operation is not idempotent, this can lead to inconsistent results since different nodes may end up with different outcomes.
Which leads to the question, how do you build in idempotency to help control concurrency for a distributed system?
In this post, we will take a look at how idempotency works in financial services, and then how it can be implemented in a distributed payment system.
Naturally idempotent vs. non-idempotent operations
At a bank, certain operations will be naturally idempotent, while others might have to be modified. For example, updating account information such as names, phone numbers etc. is naturally idempotent. You can apply those types of operation as many times as you want, and the outcome will always be the same.
But what about transactions on the account? Are they naturally idempotent?
A withdrawal on an account is not a naturally idempotent operation. If you withdraw $10 from our account, and then apply the same operation a second time, you will have withdrawn $20. This means if you get a duplicate of a withdrawal event, you could potentially introduce an error into the system. That will result in very frustrated account holders, especially if this happens frequently.
An easy fix would be to simply look at the timestamps of the transaction. If you find two transactions with the same timestamp, then you assume that one is a duplicate, and you discard it.

For smaller-scale systems, this might be sufficient. However, in highly concurrent and distributed systems, it is fairly common to find duplicate timestamps and this technique would be unreliable. For a payment and/or billing system, you need to be confident. And you don’t want to have to go back and manually audit and correct transactions.
Another solution would be to use a transaction ID so each transaction is assigned a unique identifier when it is created. You can use this identifier to enforce idempotency. Each time you apply a transaction, you check the database to see if another transaction with the same ID already exists. If it does, then you know you have found a duplicate and you can safely ignore it.
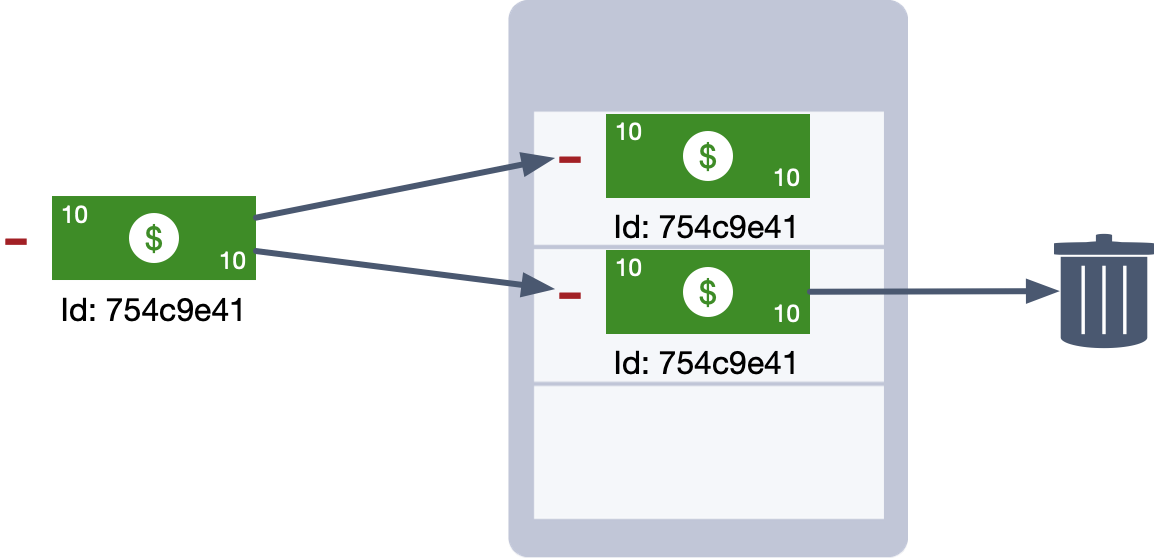
This is a basic example of how you can build idempotency into a system. But as you can imagine, with large-scale distributed systems, there’s a lot to consider.
For a full explanation of how this works, visit this blog: Idempotency and ordering in event-driven systems.
Inside Shipt’s distributed idempotent payment system
Shipt, a grocery e-commerce company owned by Target, maintains a suite of payment services that are crucial to their business model. Here we will take a look at a basic model of how a transaction flows through their payment service and how they set up idempotency.

For Shipt, it was crucial to have concurrency control in a distributed system so that they could block concurrent requests for the same payment. They built their system on CockroachDB which allows them to achieve guaranteed atomicity, consistency, isolation, and durability (ACID) all the way down to the row level.
CockroachDB also has built-in replication (that copies data to nodes while still ensuring consistency) which can make building idempotent systems substantially easier. And it enables you to run your application across multiple regions (like Shipt does) while still functioning as a single logical database.
Here’s a closer look at Shipt’s design for their payment system:
For Shipt’s database schema, there are two tables that use the regional tables topology pattern:
paymentswhich includes various attributes (dollar amount, identifier of the charge, etc.) about the paymentidempotency_tokenswhich includes metadata for a single state transition (i.e. from authorized to captured)
There are also three tables that use the duplicate indexes topology pattern:
customerspayment_methodsaccounts
The idempotency tokens table is crucial since it is used to manage the framework that Shipt built for guaranteeing correctness of the data. This table contains a lot of metadata related to payments that ensure transactions process correctly and are not executed more than once.
To guarantee serializable isolation, there’s a mechanism in place that functions as a lock or mutex. You read the value of the lock and if it’s unlocked, you write that value is locked, and commit the transaction. There are rare situations where you may forget to unlock, or the system crashes, so there’s an expiring lease on locks (60 seconds by default).
When a request is made on a payment, the idempotency tokens table is queried to ask: “is there an active idempotency token in the database for this particular payment?” This can deliver a few results:
- No, inactive = the request is processed
- Yes, active, locked = the request is rejected
- Yes, active, unlocked = the request obtains the lock, completes the operation described by the token, and proceeds to process the current request
Even with this system in place, errors can still occur. For example, if they get an error that says “insufficient funds”, that means the card has not been charged and the state transition failed and reverted to the previous state.
The system is set up to force an operation to complete so it cannot be in an ambiguous state. It either goes back to the original state (as an error or failure) or it goes forward to the intended state.
Where do I go from here?
Idempotency is not unique to financial service use cases, but for payment and billing systems that are handling people’s money, it’s crucial.
That’s why organizations are increasingly turning to CockroachDB so they can build a scalable payment and billing system designed for correctness without all the operational burden. Do you relate to Shipt’s use case? If so, get in touch to see how we can help.


